Home / Blog / 19-11-11 - Oracle and Postgres Schema Copy Process
I liked these diagrams (drawn in DrawIO). First time I’ve used the ‘sketch’ look.
Oracle Specific Solution
The limitations on access and control for the Oracle Databases mean that using the Oracle ‘export’ and ‘import’ (database dump) utility is not practical.
Oracle provides a data dictionary and stored procedure which will generate the DDL needed to create database objects. However, [this company] does not allow access to the “all database” data dictionary views, they only allow access to the view of the data dictionary for the current user / schema. To get around this, we need two stored procedures.
First a procedure to extract the DDL. This is run as the source schema user, using the source schema’s access to its own data in the data dictionary. We store this DDL in a table: SCHEMA_COPY_DDL_CACHE. We can then grant access to this table to the destination schema user.
A second procedure in the destination schema can then read the DDL and create the objects in the destination schema.
We can also grant the destination schema user access to the application tables in the source schema and then the second stored procedure can copy the data from the source schema.
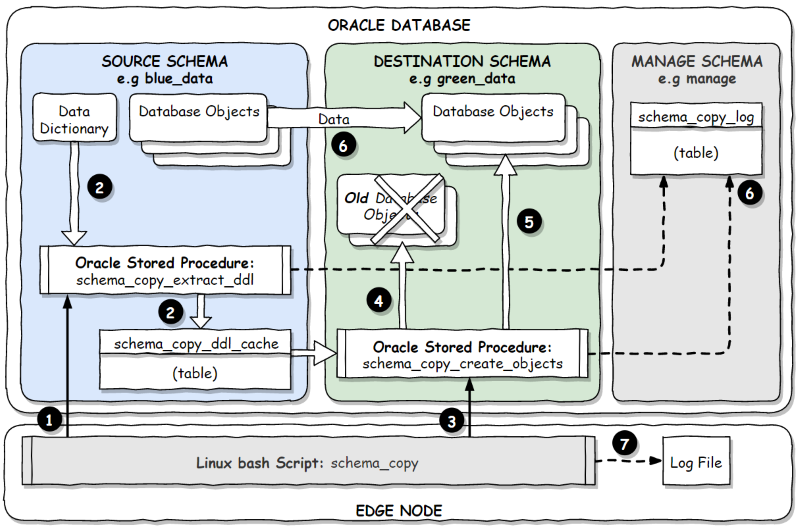
Step:
1) A Bash script running on the Edge Node server connects to Oracle as the source schema user using SQLPlus and executes the SCHEMA_COPY_EXTRACT_DDL procedure.
2) The SCHEMA_COPY_EXTRACT_DDL procedure extracts the DDL from the data dictionary and writes this to the SCHEMA_COPY_DDL_CACHE table.
3) A Bash script running on the Edge Node server connects to Oracle as the destination schema using SQLPlus and executes the SCHEMA_COPY_CREATE_OBJECTS procedure.
4) The SCHEMA_COPY_CREATE_OBJECTS procedure deletes all existing objects in the destination schema.
5) The SCHEMA_COPY_CREATE_OBJECTS procedure creates the new objects in the destination schema (with the referential integrity constraints disabled).
6) The SCHEMA_COPY_CREATE_OBJECTS procedure copies the data from the source schema to the destination schema and then enables the integrity constraints.
7) Progress (and potentially error) messages are written to the SCHEMA_COPY_LOG table and a file on the Edge Node.
Postgres Specific Solution
The Postgres solution makes use of the Postgres pg_dump utility. This is used to extract the object DDL from the source schema which is then used to create the objects in the destination schema. The data in the tables is NOT extracted - this is a very slow process. Rather than extract and import the data, this is copied using SQL from the source to the destination schema.
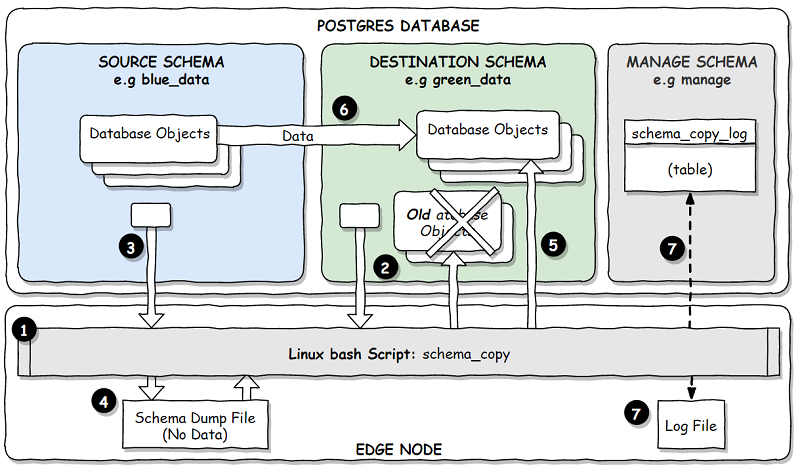
Step: 1) A Bash script running on the Edge Node server manages the schema copy process.
2) The pg_dump utility is used to extract object delete statements from the destination schema which is then use to drop all the objects in the destination schema.
3) The pg_dump utility is used to extract the DDL which will create all objects in the source schema.
4) The extract DDL is written to a file in the Edge node.
5) The psql utility is used to execute the extracted DDL to create the objects in the destination schema. The steps to create the referential integrity constraints and the Id population triggers are skipped.
6) The psql utility is used to execute SQL to copy the data from the source schema tables to the destination schema. Then the integrity constraints and Id population triggers are created.
7) Progress (and potentially error) messages are written to the SCHEMA_COPY_LOG table and a file on the Edge Node.
This page was generated by GitHub Pages. Page last modified: 24/05/17 16:31